jscpd, ou comment j’ai nettoyé le code dupliqué que l’IA m’avait laissé
Le constat qui pique
Quand je développe avec Claude Code, le rythme est confortable. Une feature, un prompt, dix minutes plus tard le code tourne, les tests passent, je commit. Multiplié par six mois sur SmartTab Organizer, j’ai accumulé pas mal de surface : wizards d’import, wizards d’export, hooks useSynced*, composants de classification, popover de diff. Beaucoup de pièces qui font des choses voisines sans être identiques.
Un jour je relis un wizard et je me dis : “tiens, ça ressemble étrangement à l’autre wizard que j’ai écrit la semaine dernière”. Je vais voir : effectivement, 80 lignes presque identiques, juste les types qui changent. Ailleurs, deux composants ConflictRow qui vivent leur vie en parallèle. Deux fonctions de validation Zod qui ne diffèrent que par un champ.
Le problème n’est pas que Claude Code a mal fait son travail. Le problème est que dans le contexte d’un seul prompt, il n’a pas vu le code qu’il avait écrit la semaine d’avant. Et moi, en tant que dev solo qui orchestre l’IA, je n’ai pas non plus tout en tête. Le résultat est mécanique : la duplication s’accumule sans que personne ne la voie passer.
C’est exactement le terrain de chasse de jscpd.
C’est quoi jscpd
jscpd, pour JavaScript Copy-Paste Detector, est un outil open source qui détecte les blocs de code identiques ou quasi-identiques dans un projet. Il supporte nativement TypeScript et JSX, sort un rapport JSON ou HTML, et ne demande pas de serveur ni de service externe : c’est un binaire Node qu’on lance comme jest ou eslint.
Il fonctionne au niveau des tokens et pas des caractères. Concrètement, ça veut dire qu’il voit les blocs structurellement similaires même si tu as renommé une variable ou changé un commentaire. C’est ce qui le rend utile sur du code généré par IA, où les renommages sont fréquents.
J’ai choisi jscpd plutôt que SonarCloud parce que je voulais garder le contrôle local : pas de service tiers, pas de compte à gérer, et un rapport directement injecté dans mes pull requests à la manière de mon reporter de tests CTRF.
La config que j’utilise
Voici mon .jscpd.json à la racine du repo :
{
"pattern": "src/{components,pages,hooks}/**/*.{ts,tsx}",
"ignore": [
"**/*.stories.tsx",
"**/*.test.ts",
"**/*.test.tsx",
"**/*.spec.ts",
"**/*.spec.tsx",
"**/node_modules/**",
"**/dist/**",
"**/.output/**",
"**/.wxt/**"
],
"format": "typescript,tsx",
"minTokens": 50,
"minLines": 5,
"gitignore": true,
"reporters": ["console", "json"],
"output": ".jscpd-report"
}Quelques points à expliquer :
Le pattern cible uniquement le code de production sous src/components, src/pages et src/hooks. Je ne scanne pas src/background ni src/utils parce que ce sont des zones où la duplication est souvent intentionnelle (logique métier qui ressemble par nature, helpers Zod parallèles).
Les minTokens: 50 et minLines: 5 sont des seuils que j’ai calibrés à la main. En dessous, on récupère trop de bruit React typique : trois lignes d’imports identiques, une signature de prop similaire, un useState('') qu’on retrouve partout. Au-dessus de 50 tokens, on est sur de vrais blocs de logique partagée.
L’exclusion des fichiers de tests et de stories est essentielle. Les tests sont structurellement répétitifs par nature, et les Storybook stories aussi. Les inclure noierait le rapport sous des centaines de faux positifs.
L’intégration GitHub Actions
Le vrai gain vient de la PR. Sans rapport visible, jscpd reste une curiosité qu’on lance une fois et qu’on oublie. Avec un commentaire sticky qui se met à jour à chaque push, on a un retour permanent sur l’état de la duplication.
Voici le workflow que j’utilise, dans .github/workflows/duplication.yml :
name: Code Duplication
on:
pull_request:
permissions:
contents: read
pull-requests: write
jobs:
changes:
name: Detect changed paths
runs-on: ubuntu-latest
outputs:
code: ${{ steps.filter.outputs.code }}
steps:
- uses: actions/checkout@v4
- uses: dorny/paths-filter@v3
id: filter
with:
filters: |
code:
- '**'
- '!docs/**'
jscpd:
name: Detect duplicated code
runs-on: ubuntu-latest
needs: changes
if: needs.changes.outputs.code == 'true' || github.event_name == 'push'
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Setup Node
uses: actions/setup-node@v4
with:
node-version: 22
- name: Run jscpd
run: npx --yes [email protected]
- name: Generate duplication markdown
if: always()
run: node scripts/jscpd-markdown.mjs > .jscpd-report/jscpd.md
- name: Publish duplication to job summary
if: always()
run: cat .jscpd-report/jscpd.md >> "$GITHUB_STEP_SUMMARY"
- name: Post sticky duplication comment on PR
if: always() && github.event_name == 'pull_request'
uses: actions/github-script@v7
with:
script: |
const fs = require('fs');
const body = fs.readFileSync('.jscpd-report/jscpd.md', 'utf8');
const marker = '<!-- jscpd-sticky-comment -->';
const fullBody = `${marker}\n${body}`;
const { data: comments } = await github.rest.issues.listComments({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
});
const existing = comments.find(c => c.body && c.body.startsWith(marker));
if (existing) {
await github.rest.issues.updateComment({
owner: context.repo.owner,
repo: context.repo.repo,
comment_id: existing.id,
body: fullBody,
});
} else {
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
body: fullBody,
});
}
- name: Upload jscpd report
uses: actions/upload-artifact@v4
if: always()
continue-on-error: true
with:
name: jscpd-report
path: .jscpd-report/Le filtre dorny/paths-filter au début sert à ne pas relancer le scan si la PR ne touche que la doc. Économie de minutes CI bien méritée.
Le marker HTML caché (<!-- jscpd-sticky-comment -->) permet de retrouver le commentaire d’une exécution précédente pour le mettre à jour plutôt que d’en créer un nouveau à chaque push. Sans ça, une PR avec 30 commits se retrouve avec 30 commentaires jscpd à scroller.
Le formateur markdown sur mesure
Le rapport JSON brut de jscpd n’est pas lisible directement. J’ai écrit un petit script Node qui le convertit en markdown bien présenté pour le commentaire de PR : scripts/jscpd-markdown.mjs.
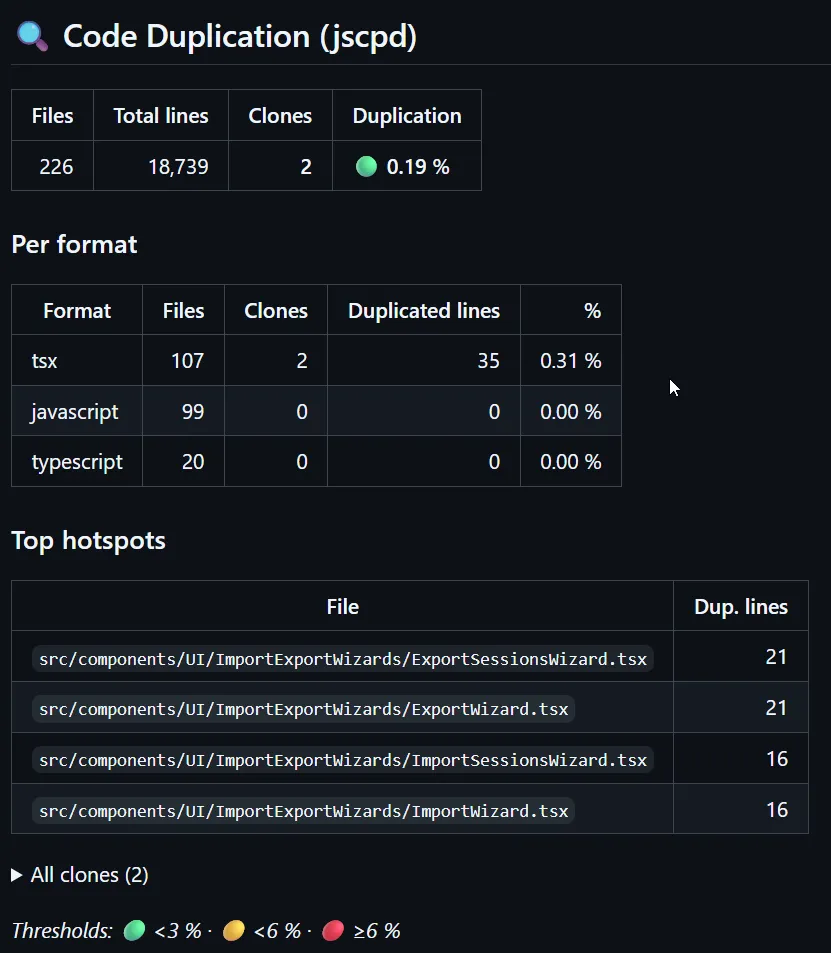
Il produit quatre sections :
- Un tableau de synthèse avec le nombre de fichiers, de lignes totales, de clones détectés et le pourcentage de duplication global, accompagné d’un emoji feu rouge / orange / vert selon le seuil.
- Une décomposition par format (typescript, tsx) avec le pourcentage par langage.
- Le top 10 des fichiers hotspots, c’est-à-dire les fichiers qui apparaissent le plus dans les paires de duplications, triés par nombre de lignes dupliquées.
- La liste de tous les clones dans un
<details>repliable, pour ne pas surcharger le commentaire mais pouvoir creuser si besoin.
Les seuils que j’ai choisis pour les emojis : vert sous 3%, orange sous 6%, rouge au-delà. Ce sont des chiffres assez stricts. Sur un projet React mature, on est souvent autour de 4 à 8% naturellement, donc ces seuils me poussent à toujours faire un peu mieux.
Le piège des faux positifs
Premier scan en local, premier choc : 47 clones détectés, 9% de duplication. Je passe la liste en revue et je réalise que la moitié n’a pas à être refactorée. C’est probablement le piège numéro un avec jscpd : tout ce qu’il détecte n’est pas à corriger.
J’ai catalogué quatre familles de faux positifs spécifiques à mon projet :
Schemas Zod parallèles. Mes fichiers dans src/schemas/ ont des structures similaires (z.object({ id: z.string(), label: z.string(), ... })) qui sont intentionnellement explicites. Les abstraire derrière un schema générique rendrait l’audit beaucoup plus difficile, et c’est précisément ce qu’on ne veut pas dans une couche de validation.
Branches i18n. Les appels getMessage('foo') répétés dans des contextes différents ne sont pas une duplication structurelle, c’est juste l’API d’internationalisation qui se répète.
Boilerplate React minimal. Les imports de Radix Themes, les useState(''), les déclarations de props : si on les compte, on a 5% de duplication “incompressible”.
Tests et stories. Déjà filtrés par la config, mais à garder à l’œil au cas où un fichier passerait à travers le filet.
Le piège dans lequel je suis tombé deux fois : extraire un composant générique pour mutualiser deux usages, puis devoir le complexifier au fur et à mesure que les deux cas divergent. La leçon : tant qu’il n’y a pas trois occurrences ou plus, j’attends. La règle du “rule of three” reste un excellent garde-fou.
Mon agent Claude qui automatise tout ça
Une fois la config en place, j’ai voulu pousser plus loin. Lancer npx jscpd en local, lire le rapport, choisir un painpoint, faire le refacto à la main, ça reste une charge mentale non négligeable quand on est dev solo.
J’ai donc créé un agent Claude Code dédié, dans .claude/agents/code-deduplicator.md. Sa mission est simple : scanner le code, présenter un top 10 des duplications les plus douloureuses, me demander laquelle traiter, puis appliquer le refacto avec des garde-fous (compile, tests, revert si échec, commit atomique).
Le score de douleur est un calcul maison :
score = lignes_dupliquées × occurrences × poids_featureLe poids_feature vaut 1.5 si la duplication touche src/background/ (le service worker, où la moindre divergence fait des bugs subtils) ou un hook useSynced* (impact storage), et 1.0 sinon. Comme ça, les duplications dans des zones critiques remontent en haut de la liste.
L’agent applique aussi des règles strictes :
- Toujours
git checkout -- .en cas d’échec compile ou test, jamais essayer de “réparer” pour sauver le commit. - Un seul refacto par invocation, pour garder des commits atomiques.
- Lecture du code source via
Readavant le refacto, sans faire confiance aveugle au rapport jscpd. - Mise à jour de tous les call sites, pas juste les deux que jscpd a remontés (un
Grepderrière pour vérifier). - Si le refacto crée un composant dans
src/components/UI/(donc inter-features), une seconde confirmation est demandée.
Le tooling repose sur le système des skills Claude. La version de jscpd est verrouillée dans skills-lock.json pour la reproductibilité, et chaque appel de l’agent fait un npx skills experimental_install au préalable pour rester synchronisé.
Quelques refactos concrets
Pour donner une idée du genre de chose qu’on extrait, voici trois refactos qui sont sortis de cet exercice.
Le cas des deux wizards d’import. J’avais ImportWizard.tsx (pour les règles de domaine) et ImportSessionsWizard.tsx (pour les sessions). Plus de 100 lignes communes : structure du wizard, gestion des étapes, classification des éléments importés, sélection des conflits. J’ai extrait :
- Un hook
useImportClassification<T>générique paramétré par le type d’élément. - Un composant
WizardModalréutilisable. - Un dossier
src/components/UI/ImportExportWizards/Shared/avecCountLabel,ConflictRowShell,DiffPopover,useDialogReset,useToggleSet.
Résultat : les deux wizards ne contiennent plus que la logique métier qui les distingue (validation Zod du payload, fonction de classification, exécution de l’import).
Les éditeurs de session et de sous-arbre d’onglets. useSessionEditor.ts et useTabTreeEditor.ts partageaient pas mal de logique de sélection / désélection / toggle d’éléments dans un arbre. Extraction d’un hook useToggleSet plus bas niveau, qui gère un Set<string> avec add, remove, toggle, setAll, clear.
Le shell de ligne sélectionnable. Trois ou quatre composants affichaient la même structure de Flex avec checkbox et label. Un SelectableRowShell est sorti, paramétrable.
Le pourcentage de duplication global est passé de 9% à 0,19% sur quelques semaines, sans aucune régression visible (les tests Vitest et Playwright sont restés verts).
Ce que j’en retiens
jscpd n’est pas magique. C’est un outil de mesure, pas un outil qui pense à ta place. Il détecte la duplication structurelle, mais c’est à toi de décider si elle mérite d’être éliminée. Sur un projet où on développe massivement avec une IA, c’est devenu indispensable parce que l’IA n’a pas la mémoire longue du codebase.
Ce qui a vraiment fait la différence pour moi, ce n’est pas l’outil tout seul, c’est la combinaison :
- jscpd qui mesure
- la CI qui rend la mesure visible dans chaque PR
- un set de faux positifs documentés que je connais par cœur
- un agent Claude qui automatise le scan, la priorisation et le refacto avec des garde-fous
Sans la dernière brique, j’aurais probablement fini par ignorer le commentaire de PR au bout de deux mois. Avec elle, je peux me dire “tiens, on fait un round de dédup ce matin”, lancer l’agent, choisir un painpoint et avoir un commit propre cinq minutes plus tard.
Si tu développes avec Claude Code ou n’importe quel agent IA et que tu sens que ton code se répète sans que tu saches où exactement, ça vaut vraiment le coup d’y mettre une demi-journée. La config jscpd plus le workflow GitHub Actions plus le formateur markdown, c’est moins de 200 lignes au total. Le retour sur investissement sur 6 mois de dev a été énorme pour moi.
Pour aller plus loin
Quelques pistes que j’ai en tête mais que je n’ai pas encore explorées :
- Mesurer aussi la complexité cognitive avec
eslint-plugin-sonarjsen parallèle, pour avoir une deuxième dimension de qualité dans la PR. - Exposer les métriques de duplication sous forme de badge dans le README, pour que le pourcentage soit visible dès la page d’accueil du repo.
- Étendre l’agent pour qu’il puisse traiter plusieurs painpoints en une seule passe quand ils sont indépendants, avec une PR de groupe.
Si tu veux discuter de ton propre setup ou de ton expérience avec jscpd, je suis joignable sur le blog de Esprit Vorace.